看到新闻寒武纪科技(Cambricon)获得了一亿美元A轮融资,而在不久前的7月,商汤科技(SenseTime)4.1亿美元B轮融资,人工智能的火势可以说越烧越大。在产业发展史中,每一场重要的产业变革总会带来新的重大机遇。如果能够在新兴产业中占据核心产业链位臵,必将能够充分享受新兴产业爆发性增长带来的红利。

今天想就寒武纪科技的融资总结一下人工智能芯片产业的生态,我们依旧从Gartner人工智能发展周期曲线开始。
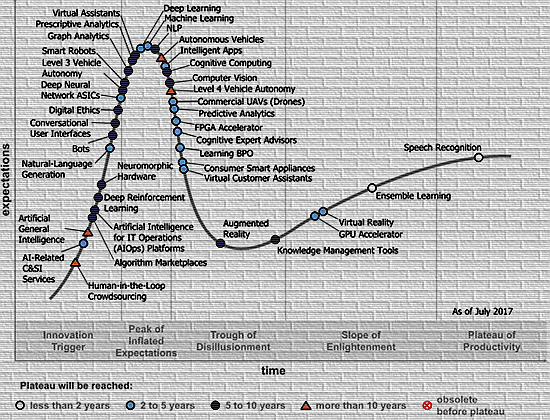
引自互联网图片
人工智能的三个核心要素是数据、算法和计算能力。目前流行的深度学习不仅在传统的语音识别、图像识别、搜索和推荐引擎、计算广告等领域证明了其划时代的价值,也引爆了整个人工智能生态向更大的领域延伸。
深度学习使得人工智能界正在面临前所未有的算力挑战,人们对计算能力的需求有指数级的提高,由于结构所限,CPU性能近年来未能呈现如摩尔定律预测的定期翻倍,原来英特尔按照“Tick-Tock”二年一个周期进行CPU架构调整,从2016年开始放缓至三年,更新迭代周期较长,传统X86架构下计算能力的提升开始滞后于摩尔定律。

因此,计算能力的需求供给出现了一个巨大的缺口,巨大的缺口同时也是时代的机遇。具有数量众多计算单元和超长流水线、具备强大并行计算能力与浮点计算能力的GPU,成为了深度学习模型训练的标配。GPU可以大幅加速深度学习模型的训练速度,相比CPU能提供更快的处理速度、更少的服务器投入和更低的功耗,并成为深度学习训练层面的事实工具标准。
来看看人工智能芯片的分类,大体上可以从处理环节、半导体架构以及应用场景三个视角来考察。
处理环节视角:训练和推断
一项深度学习工程的搭建,可分为训练(training)和推断(inteference)两个环节。

训练环节最关心的指标是速度快。训练环境通常需要通过大量的数据输入,或采取增强学习等非监督学习方法,训练出一个复杂的深度神经网络模型。训练过程由于涉及海量的训练数据(大数据)和复杂的深度神经网络结构,需要的计算规模非常庞大,通常需要GPU集群训练几天甚至数周的时间。
推断(inference)环节指利用训练好的模型,使用新的数据去“推断”出各种结论,推断环节更重视性能功耗比。如据说新的iPhone X可以通过深度神经网络模型,判断人脸是否属于手机用户而开机。虽然推断环节的计算量相比训练环节少,但仍然涉及大量的矩阵运算。在推断环节,除了使用CPU或GPU进行运算外,FPGA以及ASIC均能发挥重大作用。
目前,英伟达的GPU在训练场景中占据着绝对领导地位。2010年英伟达就开始布局人工智能产品,2014年宣布了新一代PASCAL GPU芯片架构,这是英伟达的第五代GPU架构,也是首个为深度学习而设计的GPU,它支持所有主流的深度学习计算框架。2016年上半年,英伟达又针对神经网络训练过程推出了基于PASCAL架构的TESLA P100芯片以及相应的超级计算机DGX-1。

面对深度学习Training这块目前被NVIDIA赚得盆满钵满的市场,众多巨头纷纷对此发起了挑战。
Google今年5月份发布了TPU 2.0,TPU是Google研发的一款针对深度学习加速的ASIC芯片,TPU 2.0除了推断以外,还能高效支持训练环节的深度网络加速。Google在TPU芯片的整体规划是,通过TensorFlow加TPU云加速的模式为AI开发者提供服务,Google或许并不会考虑直接出售TPU芯片。如果一旦Google将来能为AI开发者提供相比购买GPU更低成本的TPU云加速服务,借助TensorFlow生态毫无疑问会对NVIDIA构成重大威胁。

AMD目前发布了三款基于Radeon Instinct的深度学习加速器方案,希望在GPU深度学习加速市场分回一点份额,当然AMD是否能针对NVIDIA的同类产品获得相对优势尚为未知之数。

对于深度学习训练这个人工智能生态最为关键的一环,我们可以看到竞争的核心已经不是单纯的芯片本身,而是基于芯片加速背后的整个生态圈,提供足够友好、易用的工具环境让开发者迅速获取到深度学习加速算力,从而降低深度学习模型研发+训练加速的整体TCO和研发周期。Google能否构筑出足够好用的生态,让众多AI研究/开发者从CUDA+GPU转向Google,打破业界对NVIDIA的路径依赖,而这点才是真正艰难的道路。
但从市场潜力来看,未来市场规模最大的肯定是推断环节。当一项深度学习应用,如基于深度神经网络的机器翻译服务,经过数周甚至长达数月的GPU集群并行训练后获得了足够性能,接下来将投入面向终端用户的消费级服务应用中。由于一般而言训练出来的深度神经网络模型往往非常复杂,其推断仍然是计算密集型和存储密集型的,这使得它难以被部署到资源有限的终端用户设备(如智能手机)上。

由此可见,推断环节才是未来最大的潜在市场,也是人工智能芯片决胜的主战场。在推断环节还远没有爆发的时候。未来胜负尚未可知,各家技术路线都有机会胜出。
半导体架构视角:GPU、FPGA、ASIC与脑神经元
人工智能芯片,目前有两种发展路径:一种是延续传统计算架构,加速硬件计算能力,主要以3种类型的芯片为代表,即GPU、FPGA和ASIC,但CPU依旧发挥着不可替代的作用;另一种是颠覆经典的冯诺依曼计算架构,采用人脑神经元的结构来提升计算能力,以IBM TrueNorth芯片为代表。
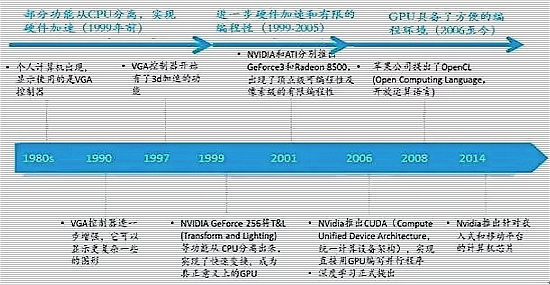
GPU芯片的发展阶段
GPU的设计出发点就是用于计算强度高、多并行的计算。GPU具有最强大的并行计算处理能力。GPU的发展经历了三个阶段:
第一代GPU(1999年以前)
部分功能从CPU分离,实现硬件加速,以GE(GEOMETRY ENGINE)为代表,只能起到3D 图像处理的加速作用,不具有软件编程特性。
第二代GPU(1999-2005年)
实现进一步的硬件加速和有限的编程性。1999年英伟达GEFORCE 256将T&L(TRANSFORM AND LIGHTING)等功能从CPU分离出来,实现了快速变换,这成为GPU真正出现的标志;2001年英伟达和ATI分别推出的GEFORCE3和RADEON 8500,图形硬件的流水线被定义为流处理器,出现了顶点级可编程性,同时像素级也具有有限的编程性,但GPU的编程性比较有限。
第三代GPU(2006年以后)
GPU实现方便的编程环境可以直接编写程序;2006年英伟达与ATI分别推出了CUDA(COMPUTER UNIFIED DEVICE ARCHITECTURE,统一计算架构)编程环境和CTM(CLOSE TO THE METAL)编程环境;2008年,苹果公司提出一个通用的并行计算编程平台OPENCL(OPEN COMPUTING LANGUAGE,开放运算语言),与CUDA绑定在英伟达的显卡上不同,OPENCL和具体的计算设备没有关系。

目前,GPU已经发展到较为成熟的阶段。谷歌、FACEBOOK、微软、TWITTER和百度等公司都在使用GPU分析图片、视频和音频文件,以改进搜索和图像标签等应用功能。GPU也被应用于VR/AR 相关的产业。此外,很多汽车生产商也在使用GPU芯片发展无人驾驶。
值得一提的是,近十年来,人工智能的通用计算GPU完全由英伟达引领。
FPGA(可编程门阵列,Field Programmable Gate Array)
FPGA即现场可编程门阵列,它不采用指令和软件,是软硬件合一的器件。FPGA是一种集成大量基本门电路及存储器的芯片,可通过烧入FPGA配置文件来来定义这些门电路及存储器间的连线,从而实现特定的功能。而且烧入的内容是可配置的,通过配置特定的文件可将FPGA转变为不同的处理器,就如一块可重复刷写的白板一样。
因此FPGA可灵活支持各类深度学习的计算任务,性能上根据百度的一项研究显示,对于大量的矩阵运算GPU远好于FPGA,但是当处理小计算量大批次的实际计算时FPGA性能优于GPU,另外FPGA有低延迟的特点,非常适合在推断环节支撑海量的用户实时计算请求(如语音云识别)。
FPGA的缺点在于进行编程要使用硬件描述语言,而掌握硬件描述语言的人才太少,限制了其使用的拓展。
ASIC(专用集成电路,Application Specific Integrated Circuit)
ASIC则是不可配置的高度定制专用芯片。特点是需要大量的研发投入,如果不能保证出货量其单颗成本难以下降,而且芯片的功能一旦流片后则无更改余地,若市场深度学习方向一旦改变,ASIC前期投入将无法回收,意味着ASIC具有较大的市场风险。但ASIC作为专用芯片性能高于FPGA,如能实现高出货量,其单颗成本可做到远低于FPGA。

Google的TPU就是采用ASIC技术。有趣的是区块链中的最新的矿机现在正在从FPGA架构大量转向ASIC架构以期更好的性能,这一市场现在的火爆程度非常像地下赌场,暗流涌动,凶猛异常。

几种芯片架构各有千秋
按照处理器芯片的效率排序,从低到高依次是CPU、DSP、GPU、FPGA和ASIC。CPU&GPU需要软件支持,而FPGA&ASIC则是软硬件一体的架构,软件就是硬件。
而按照晶体管易用性排序是相反的。从ASIC到CPU,芯片的易用性越来越强。
不可否认的是,CPU仍然是最好的通用处理器之一,而GPU具有最强大的并行计算能力,FPGA是万能芯片,而ASIC是高性能功耗比的专用芯片。
应用场景视角:训练、云部署推断、端部署推断
应用场景的训练前面已经谈过,NVIDIA目前是当仁不让的市场领导者,Google、AMD和Intel等大厂正在试图颠覆其王位。

训练场景NVIDIA的保卫战
对于NVIDIA而言,目前当务之急无疑是保卫其市场份额,总结起来是三方面的核心举措。
一方面在产品研发上,NVIDIA耗费了高达30亿美元的研发投入,推出了基于Volta、首款速度超越100TFlops的处理器Tesla,主打工业级超大规模深度网络加速;另外一方面是加强人工智能软件堆栈体系的生态培育,即提供易用、完善的GPU深度学习平台,不断完善CUDA、 cuDNN等套件以及深度学习框架、深度学习类库来保持NVIDIA体系GPU加速方案的粘性。第三是推出NVIDIA GPU Cloud云计算平台,除了提供GPU云加速服务外,NVIDIA以NVDocker方式提供全面集成和优化的深度学习框架容器库,以其便利性进一步吸引中小AI开发者使用其平台。

云部署芯片生态
由于端设备存储和计算能力的限制,每次推断(应用训练好的神经网络模型计算出翻译的结果)的端设备本地计算时间长达数分钟甚至耗尽端设备电量是无法被用户接受的,因此云端推断在人工智能应用部署架构上变得非常必要。
虽然单次推断的计算量远远无法和训练相比,但如果假设有上千万人同时使用这项服务,其推断的计算量总和足以对云服务器带来巨大压力,而随着人工智能应用的普及,这点无疑会变成常态以及业界的另一个痛点。由于海量的推断请求仍然是计算密集型任务,CPU在推断环节再次成为瓶颈。但在云端推断环节,GPU不再是最优的选择,取而代之的是,目前3A(阿里云、Amazon、微软Azure)都纷纷探索云服务器+FPGA芯片模式替代传统CPU以支撑推断环节在云端的技术密集型任务。
亚马逊 AWS 在去年推出了基于 FPGA 的云服务器 EC2 F1;微软早在2015年就通过Catapult 项目在数据中心实验CPU+FPGA方案;而百度则选择与FPGA巨头Xilinx(赛思灵)合作,在百度云服务器中部署KintexFPGA,用于深度学习推断,而阿里云、腾讯云均有类似围绕FPGA的布局,具体如下表所示。当然值得一提的是,FPGA芯片厂商也出现了一家中国企业的身影——清华系背景、定位于深度学习FPGA方案的深鉴科技,目前深鉴已经获得了Xilinx的战略性投资。
在云端推断的芯片生态中,Intel通过多桩大手笔的并购迅速补充人工智能时代的核心资源能力。首先以 167 亿美元的代价收购 FPGA界排名第二的Altera,推出CPU + FPGA 异构计算产品主攻深度学习的云端推断市场。另外,去年通过收购拥有为深度学习优化的硬件和软件堆栈的Nervana,补全了深度学习领域的软件服务能力。当然,不得不提的是英特尔还收购了领先的ADAS服务商Mobileye以及计算机视觉处理芯片厂商Movidius,将人工智能芯片的触角延伸到了设备端市场。
相比Training市场中NVIDIA一家独大,云端推断芯片领域目前可谓风起云涌,英特尔希望通过深耕CPU+FPGA解决方案,成为云端推断领域的NVIDIA。Google的TPU生态对云端推断的市场份额同样有巨大的野心。由于云端推断市场当前的需求并未进入真正的高速爆发期,多数人工智能应用当前仍处于试验性阶段,尚未在消费级市场形成巨大需求,各云计算服务商似乎有意凭借自身云服务优势,在这个爆发点来临之前布局自己的云端FPGA应用生态,这将会是一场彻头彻尾的大混战。
端部署芯片生态
随着人工智能应用生态的爆发,将会出现越来越多不能单纯依赖云端推断的设备。例如,自动驾驶汽车的推断,不能交由云端完成,否则如果出现网络延时则是灾难性后果;或者大型城市动辄百万级数量的高清摄像头,其人脸识别推断如果全交由云端完成,高清录像的网络传输带宽将让整个城市的移动网络不堪重负。未来在相当一部分人工智能应用场景中,要求终端设备本身需要具备足够的推断计算能力,而显然当前ARM等架构芯片的计算能力,并不能满足这些终端设备的本地深度神经网络推断,业界需要全新的低功耗异构芯片,赋予设备足够的算力去应对未来越发增多的人工智能应用场景。
端部署芯片主流场景包括智能手机、ADAS、CV设备、VR设备、语音交互设备以及机器人。
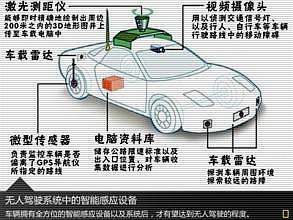
在端部署芯片领域,我们看到的是一个缤纷的生态。因为无论是ADAS还是各类CV、VR等设备领域,人工智能应用仍远未成熟,各人工智能技术服务商在深耕各自领域的同时,逐渐由人工智能软件演进到软件+芯片解决方案是自然而然的路径,因此形成了丰富的芯片产品方案。但我们同时观察到的是,NVIDIA、英特尔等巨头逐渐也将触手延伸到了这一领域,意图形成端到端的综合人工智能解决方案体系,实现各层次资源的联动。
FPGA未来大有可为
人工智能在推断环节应用刚起步,云端要比前端设备发展速度更快。
云计算巨头纷纷布局云计算+FPGA芯片,首先因为FPGA作为一种可编程芯片,非常适合部署于提供虚拟化服务的云计算平台之中。FPGA的灵活性,可赋予云服务商根据市场需求调整FPGA加速服务供给的能力。比如一批深度学习加速的FPGA实例,可根据市场需求导向,通过改变芯片内容变更为如加解密实例等其他应用,以确保数据中心中FPGA的巨大投资不会因为市场风向变化而陷入风险之中。
另外,由于FPGA的体系结构特点,非常适合用于低延迟的流式计算密集型任务处理,意味着FPGA芯片做面向与海量用户高并发的云端推断,相比GPU具备更低计算延迟的优势,能够提供更佳的消费者体验。
FPGA最大的优点是动态可重配、性能功耗比高,非常适合在云端数据中心部署。近两年,全球七大超级云计算数据中心包括IBM、Facebook、微软、AWS以及BAT都采用了FPGA服务器。在这方面,中国和美国处以同一起跑线。
人工智能算法正处于快速迭代中,当前人工智能算法模型的发展趋势是从训练环节向推断环节走,这个过程非常有利于FPGA未来的发展。人工智能算法正处于快速迭代中采用了搭建在FPGA上的硬件框架ESE,获得了高一个数量级的能量效率提升。
FPGA行业呈现双寡头格局。从Gartner公开报告中我们可以看到,FPGA器件的厂家主要有Xilinx(赛灵思)、Altera(阿尔特拉)、Lattice(莱迪思)和Microsemi(美高森美),这四家公司都在美国,总共占据了98%以上的市场份额。其中全球份额Xilinx占49%,另一家Altera占39%,剩余的占比12%。
近两年,FPGA行业展开了多项并购,但是对竞争格局影响不大。2015年6月,英特尔宣布以167亿美元收购Altera(阿尔特拉)。目前国内能够生产FPGA的上市公司仅有紫光国芯(002049),而非上市公司有智多晶和AgateLogic等。
人工智能并不是一个单独的存在,而必须要和其他产业结合起来才能创造提升效率,创造价值。